The Genomes Unzipped members have spent a lot of time discussing their 23andMe genotyping data, and therefore it makes sense to follow-up on the recent scientific publications from this company. This new publication from 23andMe is particularly newsworthy because while 23andMe had already reported new findings for common traits, this is as far as I can tell the first time that a direct-to-consumer genetics company has tackled a major disease. Here, this is Parkinson’s disease (PD) a relatively common condition which has been a focus of 23andMe for a long time now. This 23andMe study identifies two new PD loci. They also replicated the vast majority of published findings, hence confirming the validity of their approach and confirming their role as a significant player in the field of common disease genetics.
I should also mention that I was involved in a companion paper that will be published shortly in the same journal (only slowed down by technical issues, hopefully only a matter of days) and therefore my enthusiasm about this study may be somewhat biased.
So what is this study about?
Roughly two years ago 23andMe announced the launch of the Parkinson’s Disease (PD) genetics Initiative. The idea was to use a grant provided by Google co-founder Sergey Brin, a man dedicated to promoting PD research, to make the 23andMe subscription nearly free for PD patients. Increasing the recruitment of patients would then enable larger scale genetic association studies. The price was chosen to be very low: purchasing for $25 a kit sold to the rest of the population for $399 is an attractive offer, especially when this offer is coordinated with the Michael J. Fox Foundation and the Parkinson’s institute to attract the attention of PD patients. In addition to the scientific interest for 23andMe, this is also a remarkable advertisement for the company and it makes perfect sense for 23andMe to start such initiatives.
How successful was the recruitment?
It is hard to guess what the expectations really were, but initial posts suggested a long-term goal of 10,000 PD patients. Overall, the recruitment appears to have worked well. In March of this year 23andMe announced that they had recruited close to 5,000 PD cases and 3,500 PD cases are reported in this recent paper. For these PD individuals the consent is identical to the one provided to non-PD customers and this large collection of controls provide a natural control set for the PD study. The number of samples is still the limiting factor though hence the need for a collaboration with the International Parkinson’s Disease Genomics Consortium to provide additional evidence at these new loci (this collaboration forms the basis of that soon-to-be-published companion paper I contributed to).
What have they found?
The same (good) things most scientists find when they put together a new genetic association study better powered than the previous ones: additional loci that contribute to the risk of PD in the population. They also worked out heritability estimates for PD using modern techniques and found the genetic component to be comparable to Crohn’s disease , but lower than type 1 diabetes and quite a bit lower than bipolar disorder. But I should say here that I find these heritability estimates rather counter-intuitive given the stark contrast in genetic findings between Crohn disease and bipolar disorder for example (and even PD). I guess the future will tell whether my concerns are justified.
What can they do in the future?
First of all they should (and certainly will) do what all researchers in the field do these days: combine their study with others to form a large-scale meta-analysis in order to identify new loci for PD. But beyond that, the possibilities offered to 23andMe go way beyond such conventional approaches. A key strength is the ability to use questionnaires to gather new data from cases or controls: family history, environmental exposure… So if a specific hypothesis comes up about the role of an environmental trigger, potentially in combination with a genetic factor, they will be in a position to obtain relevant data without genotyping more patients, just by sending requests for information to the individuals with usable genotype data. In a sense, they do not need to ask the right questions the first time, which is certainly a luxury that most researchers do not have. They can also extend the idea to other diseases and this process is certainly ongoing as well.
But they can do something even more unique: once DNA sequencing becomes available as a commercial product (and that should be quite soon), this vast collection of genotype data will show a large number of rare genetic variants of potential medical interest. It will then become possible to identify patients who carry these very rare genotypes and ask them what rare traits they may share as a consequence of this. This idea is similar to the one put forward by the Cambridge Bio-Resource (based in the UK), but on a bigger scale and not as localized geographically. My intuition is that as genetics move toward more applied and translational questions this resource will become very valuable. I certainly look forward to seeing that type of research being published.
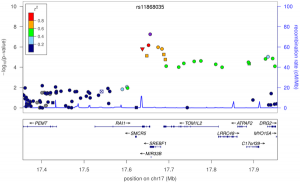
The graphic at the top of the post is from Figure 1 of the PLoS paper, and shows one of the PD associated regions.








 RSS
RSS Twitter
Twitter
What is most impressive about the study is the rapid recruitment of large numbers of cases. A methodological question though– the paper notes that the GWAS “controlled for age”, which on the surface seems appropriate. But looking at Table 1, there is a 16 year difference in the mean ages of cases vs controls. Would it have made more sense to simply exclude any controls under, say 40 (as the prevalence of PD is extremely low, and presumably there will be folks who will go on to develop PD in the future)? I would think that the ideal control group would actually be those aged >65 or so with no evidence of PD…. or match for age, since age alone is probably the strongest risk factor for PD. The use of “age decile” in the AUC wouldn’t seem to really address this issue.
Looking forward to the companion paper!
I’m one of the authors (CBD) on the 23andMe study.
There’s a delicate trade-off between (1) the loss of power that comes from misclassification of controls (i.e., individuals who don’t have PD now, but go on to develop it in the future), and (2) the gain in power that comes from having a larger sample size. The following table shows the power to detect a genetic variant with MAF 0.2 and odds ratio 1.2 [based on a modification of the method described in PMID 12145550] assuming 3426 cases and a variety of control individual misclassification rates:
control misclassification rate
n_controls 0.00 0.01 0.02 0.07
any age 29624 62% 60% 57% 46%
age 40+ 20549 57% 55% 53% 41%
age 65+ 8535 39% 37% 35% 26%
Lifetime risk estimates for PD vary a bit depending on the assumptions used (e.g., 2% [PMID 11781119] to 7% [PMID 19188574]). Even in the most pessimistic scenario, however, the power afforded by using our full control set at a 7% misclassification rate (46%) exceeds the power from using a 65+ cohort with no misclassification. Thresholding at age 40 doesn’t really reduce the misclassification rate in the control set since the remaining lifetime risk of developing PD at age 40 doesn’t differ substantially from an individual’s overall lifetime risk of PD.
For the GWAS analysis, matching based on age is possible, but including age as a covariate in the logistic regression model is a fairly standard approach to correcting for age that avoids the loss of power due to decreased sample sizes.
For the AUC analysis, we actually did use a sophisticated form of matching beyond the “age deciles” used when creating the various folds for the cross-validation. It’s somewhat buried in the Supplementary Information, but we used a particular subclassification approach known as “full matching” when computing covariate-adjusted AUCs that matched based on sex, age, and ancestry covariates.
Thanks Tom for the clear explanation– with power tables to boot!
With regards
Ever heard of recall bias?
Looking for a suitable reference, I came across this:
http://www.gulflink.osd.mil/library/randrep/pesticides_survey/mr1018.12.appd.html
This is why prospective studies are so valued in epidemiology.
@Neil
Not sure I see how genotype-specific recall bias would work…
@Luke
um, I was responding to this:
i.e. the recall bias is due to health status, not genotype.
So, for example, this study:
http://www.ncbi.nlm.nih.gov/pubmed/16802290
Ascherio, A et al (2006)
Pesticide exposure and risk for Parkinson’s disease.
Ann Neurol. Aug;60(2):197-203.
is prospective, and this study:
http://www.biomedcentral.com/1471-2377/8/6
Hancock, DB et al (2008)
Pesticide exposure and risk of Parkinson’s disease: A family-based case-control study
BMC Neurology, 8:6doi:10.1186/1471-2377-8-6
deliberately chose a family-based approach to mitigate against differential recall.
Well the prime use will be to use the new data gathering to dig deeper into the mechanism of associations. e.g. were people with the disease who carry the risk allele also more likely to report living in a house build before 1970 than those who don’t, etc.
Overall, it seems like the possibility of recall bias is just another potential confounding factor that you will have to design around. You just have to make sure that you ask questions, like the above, that are likely to be more robust to the potential bias.
Hi Neil,
Yes recall bias is an issue, but it’s not a reason to discard any possibility of getting useful information from that sort of design.Some data points are factual enough and other questions can be asked in a way that does not lead to a specific answer. It’s like anything in science: it has to be done well to work.
Also: I have not thought it through at all but I guess that, assuming that we look for genetic-environmental combinations, and assuming that individuals do not know their genetic risks, correlating the answers with the genetic risk should be quite robust to any bias (a Mendelian randomization of some sort).
Hi Vincent
I don’t think that is what Mendelian randomisation is, but await your next blog on the topic :-)
However, bias is much easier to handle for something you can measure, than for something you have to ask.
So, for example, some of the more convincing evidence on the relationship of pesticide use and PD has been based on calculations of pesticide exposure from self-reported lists of residential and work addresses, rather than relying on recall of exposure patterns.
Amphetamine use has also been linked with PD – getting unbiased information on that is going to be tough.
Recall and selection bias in questionnaire-based studies are pretty big issues for nutritional epidemiology studies where participants are asked to recall past food consumption. For example, this meta-analysis suggests that the reported link between eating more fruits and vegetables and lower risk of breast cancer doesn’t hold up if you look at prospective studies instead of case-control studies.
http://jama.ama-assn.org/content/293/2/183.long
As with all GWAS, the value lies in generating good hypotheses to test: whether rare variants are found linked to the SNPs, or whether the SNPs lead to better mechanistic understanding of PD (especially interaction with environment).
Medications to treat Parkinson’s disease can cost a patient between $1,000 and $7,000 per year.
In the United States, Parkinson’s disease costs about $25 billion each year, paid for by people with Parkinson’s, their families, health insurers, disability insurers, SSI, SSDI, Medicaid and Medicare. Michigan’s share of those costs is more than $1.25 billion. (Yr. 1999-2000).
Medical-rights.com